The rapid evolution of artificial intelligence has fundamentally altered the technological landscape. While breakthrough models and sleek user interfaces capture the public's imagination, the true engine of this revolution operates quietly behind the scenes. We are talking about the physical and virtual backbone of modern innovation: AI infrastructure. Staying informed on the latest 2026 ai infrastructure news is no longer just a technical necessity; it is a critical business imperative for any organization looking to remain competitive in the digital age.

In the current ecosystem, AI is fundamentally reshaping how we approach computing, networking, storage, and power management. As models grow exponentially in size—moving from billions to trillions of parameters—the hardware and software stacks required to train and run them must scale accordingly. This article provides comprehensive ai technology insights, diving deep into the hardware leaps, architectural shifts, deployment strategies, and sustainability efforts that define the modern era of machine learning.
Whether you are a CIO mapping out your enterprise compute roadmap 2026, a data center manager navigating thermal challenges, or an IT architect exploring cloud deployments, understanding the pulse of the industry is essential. Let's explore the most critical developments shaping the future of AI through the lens of today's 2026 ai infrastructure news.
The Current Landscape: Unprecedented Growth and Investment
If you scan the ai infrastructure news today, one theme dominates the headlines: unprecedented scale. The demand for compute has outpaced Moore's Law, forcing the industry to rethink the traditional data center from the ground up.
Surging Capital Inflows
Recent ai infrastructure investment news highlights a staggering influx of capital. Tech giants, venture capital firms, and sovereign wealth funds are pouring hundreds of billions of dollars into building the next generation of supercomputers. This funding is not just going toward GPUs; it is being distributed across the entire supply chain, including power generation, cooling technologies, and advanced networking fabrics.
What the Headlines are Saying
Browsing through data center news today ai infrastructure reveals a distinct shift from generalized compute to purpose-built environments. Data centers are no longer just warehouses for standard x86 servers. They are becoming highly specialized, dense environments capable of managing massive thermal and power loads. The latest cloud ai infrastructure news frequently details how major providers are securing vast plots of land, negotiating dedicated power purchase agreements (often nuclear or renewable), and completely redesigning their facility architectures to accommodate the weight and power requirements of modern AI clusters.
Major AI Hardware Updates and Architecture Shifts
The heart of any AI stack is its compute engine. The latest ai hardware updates have introduced processors that defy traditional performance metrics, pushing the boundaries of what is physically possible on a piece of silicon.
Nvidia Blackwell vs Hopper Architecture Comparison
When discussing the bleeding edge of AI hardware, the conversation inevitably centers on Nvidia. The Nvidia Blackwell vs Hopper architecture comparison is a masterclass in technological evolution.
Released in 2022, the Hopper architecture (exemplified by the H100) revolutionized the industry with its dedicated Transformer Engine, allowing for massive performance leaps in training large language models (LLMs) using FP8 precision. However, the sheer size of newer models demanded even more.
Enter the Blackwell architecture. Blackwell is not just an iterative update; it is a massive leap forward.
- Second-Generation Transformer Engine: Blackwell introduces support for FP4 (4-bit floating point) precision, effectively doubling the compute and memory bandwidth over Hopper without sacrificing model accuracy during inference.
- Massive Scale: The Blackwell B200 GPU packs over 200 billion transistors, utilizing a multi-die architecture connected by a blisteringly fast interconnect.
- Cost and Energy Efficiency: For massive trillion-parameter models, Blackwell can reduce cost and energy consumption by up to 25x compared to Hopper, an essential factor as organizations look to scale sustainably.
The Role of Memory in AI
Compute power is useless if the processor is starved for data. This brings us to the high-bandwidth memory benefits for LLMs. Modern language models are heavily memory-bound, meaning their performance is often bottlenecked by how fast data can be shuttled between the memory and the compute cores, rather than the speed of the compute cores themselves.
The integration of HBM3 and HBM3e (High Bandwidth Memory) allows terabytes of data to flow per second. This is crucial for running generative AI, where the "batch size" and the "context window" (how much text the AI can remember at once) directly correlate to memory capacity and speed.
Hardware-Software Co-Design for Neural Networks
One of the most fascinating ai infrastructure trends is the move toward hardware-software co-design for neural networks. Hardware is no longer developed in a vacuum. Companies are designing custom silicon specifically tailored to the mathematical operations of specific software frameworks (like PyTorch or TensorFlow). By optimizing compilers, drivers, and the silicon simultaneously, vendors can squeeze out significantly more performance—often achieving hardware utilization rates previously thought impossible.

Overcoming the Thermal and Power Wall
As we pack more billions of transistors onto a chip, the power density of server racks is skyrocketing. Traditional data center racks consumed between 5 to 10 kilowatts (kW) of power. Today, a single rack of AI servers can easily exceed 100 kW. This reality dominates ai data center infrastructure news, including a large share of 2026 ai infrastructure news coverage focused on power availability and cooling retrofits.
Embracing Advanced Cooling
The question on every data center manager's mind is: what is liquid cooling in ai data centers, and is it necessary?
The short answer is yes. Air cooling has reached its physical limits. Moving enough air to cool a 120 kW rack would require fans so loud and powerful they would damage the equipment. Liquid cooling utilizes the superior heat transfer properties of fluids (usually water or specialized dielectric fluids) to manage thermals.
There are primarily two approaches gaining traction:
- Direct-to-Chip (D2C) Cooling: Cold plates are attached directly to the hottest components (GPUs and CPUs). Liquid flows through these plates, absorbing heat and carrying it away to a heat exchanger.
- Immersion Cooling: Entire servers are submerged in a non-conductive, specialized fluid that efficiently absorbs heat. This eliminates the need for fans entirely, drastically reducing noise and mechanical failure rates.
Reducing Power Consumption in Machine Learning Clusters
Beyond cooling, reducing power consumption in machine learning clusters is a massive priority. It is not just about being green; it is about keeping the power grid stable and managing astronomical electricity bills.
Strategies include:
- Dynamic Voltage and Frequency Scaling (DVFS): Adjusting the power consumption of GPUs dynamically based on the current workload.
- Job Scheduling Optimization: Running heavy training jobs during off-peak hours when grid energy is cheaper and more abundant.
- Architectural Efficiency: Upgrading to architectures like Blackwell that offer significantly higher performance-per-watt.
Networking and Storage: The Unsung Heroes of AI
In the world of ai compute infrastructure news, GPUs often steal the spotlight. However, deploying thousands of GPUs is useless if they cannot communicate with each other seamlessly.
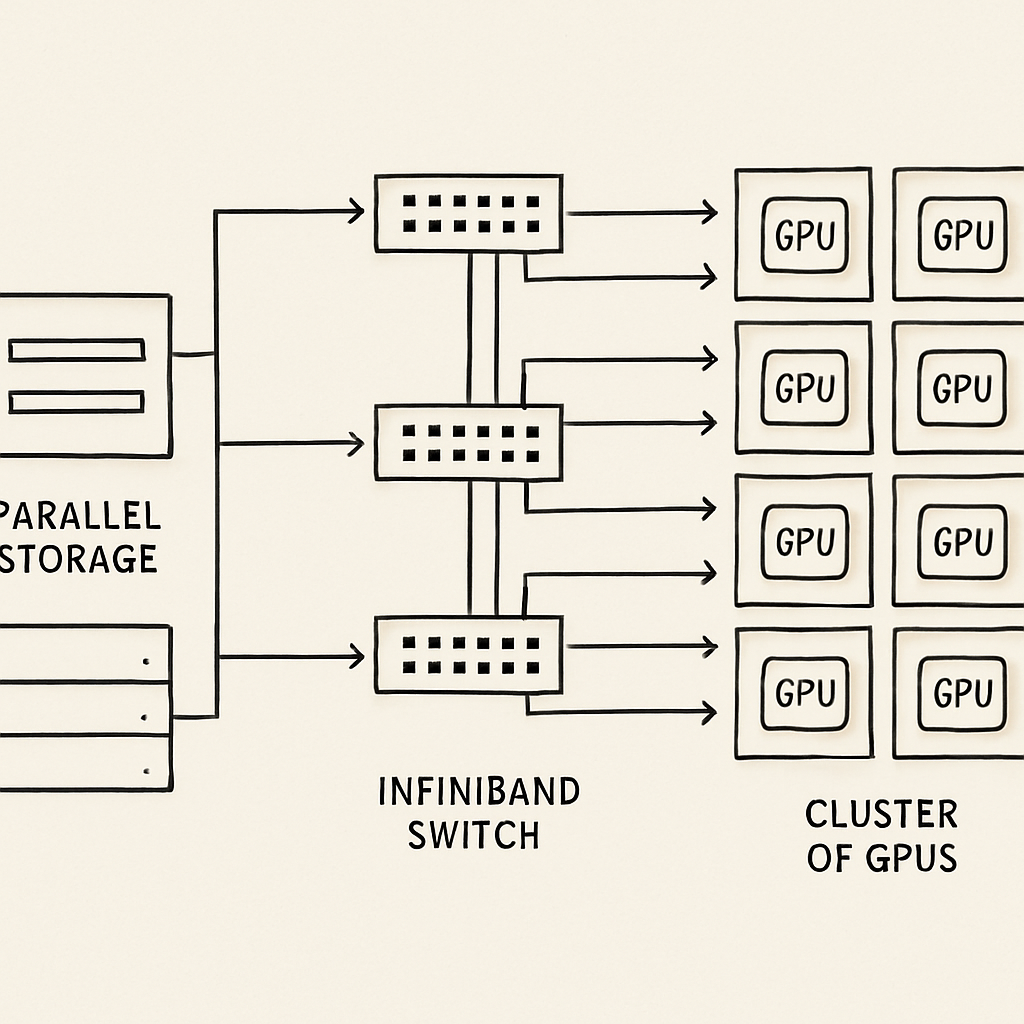
Solving Networking Bottlenecks with InfiniBand
When training a massive AI model, the workload is distributed across thousands of GPUs. They must constantly share data (gradients and weights) in real-time. If the network stutters for even a millisecond, the entire cluster halts, waiting for the slowest link.
This is why solving networking bottlenecks with InfiniBand is a core focus for enterprise AI. While traditional Ethernet is ubiquitous and highly flexible, InfiniBand was purpose-built for high-performance computing (HPC). It offers ultra-low latency, massive bandwidth, and lossless data transmission. Features like RDMA (Remote Direct Memory Access) allow GPUs to read and write directly to the memory of other GPUs across the network without involving the CPU, drastically reducing latency.
While advanced Ethernet protocols (like RoCE - RDMA over Converged Ethernet) are catching up, InfiniBand remains the gold standard for massive, synchronous AI training clusters.
Scalable Storage Solutions for Large Datasets
Generative AI is hungry for data. Whether it is billions of images, years of video footage, or the entire public internet's worth of text, the storage infrastructure must keep up.
Scalable storage solutions for large datasets are evolving. Traditional NAS (Network Attached Storage) and SAN (Storage Area Network) setups often struggle with the parallel read requests generated by thousands of GPUs simultaneously fetching training data.
Modern ai systems development relies on parallel file systems (like Lustre or Spectrum Scale) and high-performance object storage. These systems distribute data across multiple storage nodes, allowing massive parallel throughput, ensuring the GPUs are constantly fed with data and never sitting idle.
Strategic Deployment: Cloud, Edge, and On-Premise
Where should you build your AI? This is a foundational question for any organization. The latest ai tech news highlights a fragmented approach, with businesses choosing environments based on their specific security, cost, and latency needs.
On-Premise vs Cloud AI Deployment Costs
Understanding on-premise vs cloud ai deployment costs requires a deep dive into the Total Cost of Ownership (TCO).
The Cloud Route: For many, the cloud is the default entry point. It offers immediate access to state-of-the-art hardware without massive upfront capital expenditure (CapEx). However, renting high-end GPUs by the hour becomes staggeringly expensive for continuous, 24/7 training workloads. Furthermore, moving petabytes of data into and out of the cloud incurs high egress fees.
The On-Premise Route: Building an on-premise AI data center requires massive CapEx—buying servers, upgrading power, and installing liquid cooling. However, for organizations with sustained, long-term AI workloads, the operational expenditure (OpEx) over a three-to-five-year period is often significantly lower than cloud hosting. Furthermore, on-premise offers complete data sovereignty, which is critical for highly regulated industries.
Hyperscale Cloud Service Provider Expansion
Despite the cost of continuous compute, the cloud remains indispensable. Hyperscale cloud service provider expansion is happening at a breakneck pace. Providers like AWS, Microsoft Azure, and Google Cloud are building out exclusive "AI regions" designed from the ground up for machine learning.
They are also offering custom silicon as an alternative to standard GPUs. Google's TPUs (Tensor Processing Units), AWS's Trainium/Inferentia chips, and Azure's Maia accelerators provide cost-effective, highly optimized alternatives for specific AI workloads. Tracking this cloud ai infrastructure news is vital for companies looking to optimize their cloud spend—and it remains a recurring theme across 2026 ai infrastructure news.
Edge Computing Integration for Real-Time Inference
Not all AI happens in a massive data center. As AI becomes integrated into autonomous vehicles, factory robotics, and medical devices, sending data back to the cloud for processing introduces unacceptable latency and security risks.
Edge computing integration for real-time inference solves this by placing lightweight, low-power AI processors physically close to the data source. For example, a quality-assurance camera on an assembly line can use a localized edge device to instantly run an AI model that detects manufacturing defects in milliseconds, without relying on an internet connection.

Practical Strategies for the Enterprise Compute Roadmap 2026
Navigating these complex ai infrastructure updates requires a solid strategy. For IT leaders, establishing a robust enterprise compute roadmap 2026 is essential to avoid wasted investments and technological dead ends.
Building a Modular AI Tech Stack
The days of monolithic vendor lock-in are fading. Today, agility is survival. Building a modular ai tech stack means designing an infrastructure where components—whether it is the orchestration layer (like Kubernetes), the storage tier, or the compute nodes—can be swapped out or upgraded independently.
By adopting open standards and containerized applications, organizations can seamlessly shift workloads from local servers to the cloud, or migrate from one GPU vendor to another as the market dictates.
Upgrading Legacy Servers for Generative AI
Not every company has the budget to build a new AI data center from scratch. A common challenge is upgrading legacy servers for generative ai.
While you cannot turn a ten-year-old CPU server into an AI powerhouse, you can strategically augment existing infrastructure. Actionable steps include:
- Evaluate PCIe Lanes: Ensure your existing motherboards have the bandwidth (PCIe Gen 4 or Gen 5) to support modern accelerators.
- Power and Cooling Audits: Adding robust GPUs to legacy servers will spike power draw. Ensure your Power Supply Units (PSUs) and rack cooling can handle the load.
- Adopt SmartNICs and DPUs: Offloading networking and security tasks from the main CPU to Data Processing Units (DPUs) can free up valuable resources and breathe new life into older servers acting as storage or orchestration nodes.
Future-Proofing Data Center Hardware
How do you buy hardware today knowing something twice as fast will be released next year? Future-proofing data center hardware requires a shift in mindset.
- Invest in Infrastructure, not just Silicon: While GPUs age rapidly, investments in upgraded facility power grids, reinforced server racks (capable of holding 3000+ lbs), and versatile liquid cooling manifolds will serve your organization through multiple generations of processor upgrades.
- Design for Density: Plan your data center floor for high-density racks rather than sprawling rows of low-power servers. This minimizes the physical footprint and reduces the length of expensive optical networking cables.
Sector-Specific Applications: Tailoring the Infrastructure
The broader ai infrastructure news often speaks in generalities, but the reality is that infrastructure must be tailored to the specific use case. Different industries require vastly different configurations.
Security and Privacy: AI for Legal Research
Consider the legal industry. Utilizing ai for legal research—such as analyzing massive archives of case law, drafting contracts, or performing e-discovery—represents a massive leap in productivity. However, legal data is highly sensitive and subject to strict confidentiality rules (like attorney-client privilege).
For this sector, the infrastructure cannot rely on public, multi-tenant cloud APIs where proprietary data might be ingested into a public model.
- Private LLMs: Law firms are building robust on-premise environments to host open-source or proprietary models securely behind their firewalls.
- RAG Infrastructure: They require incredibly fast SSD storage arrays to support RAG (Retrieval-Augmented Generation). RAG allows the AI to securely pull specific, factual data from a firm's private database in real-time to augment its answers, ensuring accuracy and preventing "hallucinations."
- Strict Access Controls: The networking infrastructure must implement zero-trust security architectures at the hardware level, ensuring that data is encrypted both in transit and at rest.
Uncovering Business Value with AI Technology Insights
Across all sectors, the goal of modernizing infrastructure is to generate actionable ai technology insights. Retailers are using AI infrastructure to process thousands of live video feeds to optimize store layouts and manage inventory. Financial institutions use massive compute clusters to run complex risk-analysis models in milliseconds, detecting fraudulent transactions before they are completed. In every instance, the speed, reliability, and security of the underlying infrastructure directly dictate the business value of the AI application.
How to Optimize AI Workload Efficiency
Buying the best hardware is only half the battle. If your software and orchestration are poorly configured, you will waste vast amounts of compute power. Knowing how to optimize ai workload efficiency is what separates competent IT teams from elite ones.
Here are actionable tips to ensure you are getting the most out of your investments:
1. Implement Advanced Orchestration
Use robust orchestration tools specifically designed for machine learning, such as Kubernetes combined with advanced schedulers like Run:ai or Slurm. These tools allow you to pool GPU resources dynamically, meaning if one user isn't fully utilizing a GPU, those compute cycles can be automatically allocated to another user's job.
2. Utilize Quantization and Model Pruning
You do not always need maximum precision for inference. Techniques like quantization reduce the mathematical precision of a model's weights (e.g., from 16-bit to 8-bit or even 4-bit) with a negligible drop in accuracy. This drastically reduces the memory footprint and speeds up inference, allowing you to run larger models on cheaper, less powerful hardware.
3. Right-Size Your Instances
One of the most common mistakes in cloud deployments is over-provisioning. Not every task requires an H100 GPU. Data preprocessing, data loading, and model evaluation can often be done on powerful CPUs or mid-tier GPUs. Reserve your most expensive, high-bandwidth accelerators strictly for the heavy lifting of model training and high-throughput inference.
4. Monitor and Profile Relentlessly
Use profiling tools (like Nvidia Nsight) to identify bottlenecks. Is your GPU sitting idle at 30% utilization while waiting for the storage drive to feed it data? Profiling helps you identify where the bottleneck lies so you can upgrade the right component, rather than blindly throwing more money at GPUs.
The Broader Impact: 2026 AI Infrastructure News Today
As we look toward the horizon, the 2026 ai infrastructure news today points toward an increasingly interconnected and complex ecosystem. The days of siloed IT departments are over. Building and maintaining an AI ecosystem requires tight collaboration between facility engineers (power and cooling), network architects (InfiniBand and optical routing), data scientists (model optimization), and cybersecurity experts.
Furthermore, the geopolitical landscape is increasingly shaping the 2026 ai infrastructure news. Export controls on advanced microchips, investments in domestic semiconductor manufacturing, and global competition for critical resources (like rare earth metals and energy grid capacity) are all impacting how and where AI infrastructure is built.
Staying abreast of these ai infrastructure updates is vital. A strategic decision made today regarding hardware architectures, deployment models, or software orchestration will echo for years, heavily influencing an organization's agility, cost structure, and ultimate success in the AI era.
Conclusion
The realm of artificial intelligence is moving at a breakneck pace, but the models and algorithms are only as good as the foundation they run on. From understanding the nuances of the Nvidia Blackwell vs Hopper architecture comparison to navigating the complex decisions surrounding on-premise vs cloud ai deployment costs, the infrastructure landscape is fraught with both challenges and immense opportunities.
As power demands soar, innovations like liquid cooling in ai data centers and solving networking bottlenecks with InfiniBand are moving from niche HPC technologies to standard enterprise requirements. Meanwhile, building a modular ai tech stack and focusing on hardware-software co-design for neural networks ensures that businesses can remain agile and efficient.
The ultimate takeaway from the latest 2026 ai infrastructure news is this: infrastructure is no longer a passive utility. It is an active, strategic enabler. By prioritizing efficiency, scalable storage, intelligent networking, and sustainable power management, organizations can future-proof their operations and fully harness the transformative power of AI today and well into the future.
Build Better AI Prompts with ZETRAXAI →
Use ZETRAXAI to generate optimized prompts for ChatGPT, Midjourney, Veo 3, and more — completely free.
Try ZETRAXAI Free